URL Classifier
Contents
Summary
This project is about constructing a URL classification model using the TensorFlow library. The model is trained to classify URLs into three categories: ‘left’, ‘central’, and ‘right’. The project is organized as a Jupyter notebook (Classifier_Demo.ipynb) and a utility script (utils.py).
GitHub Repository
Check the source codes out on my GitHub repo.
Project Details
Initialization
Firstly, the project starts with setting up the environment and importing necessary packages, including TensorFlow, pandas, numpy, and others.
-
Environment Setup
The environment setup includes mounting Google Drive and specifying the directory for data and model resources.
# URL Classifier
""" Prepare Notebook for Google Colab """
# Mount Google Drive
from google.colab import drive
drive.mount('/content/drive')
# Specify location
module_dir = (
"/content/drive/My Drive/Demo"
)
# Add material directory
import sys
sys.path.append(module_dir)
-
Install prerequisite libraries
The code imports the necessary libraries and checks if a GPU is available for TensorFlow to use.
""" Install prerequisite libraries """
# Some of the codes in this notebook may return error
# with different versions of the packages listed below.
# Please install the packages with the versions specified below.
!pip3 install wordninja==2.0.0 # for splitting joined words
!pip3 install scikit-learn==0.23.2 # for one-hot encoding
!pip3 install lime==0.2.0 # for explaining model predictions
# Uncomment to install the libraries if necessary
#!pip3 install tensorflow==2.0.0 # if you use TensorFlow w/out GPU
!pip3 install tensorflow-gpu==2.0.0 # if you use TensorFlow w/ GPU
-
Import Packages to Use
-
pandas: A powerful data manipulation library in Python. It is used for loading and manipulating data in this code. -
pickle: Used for serializing and de-serializing Python object structures. -
wordninja: A package that uses a language model to split concatenated words, which is useful for splitting URLs into individual words. -
tensorflow: A machine learning framework used to build the neural network model for classification. It’s also used to create dataset pipelines and check for available GPUs. -
tensorflow.keras.preprocessing.text.Tokenizer: A class for vectorizing texts, or/and turning texts into sequences. -
tensorflow.keras.preprocessing.sequence.pad_sequences: A function used to pad sequences to the same length. -
matplotlib.pyplot: A plotting library used for data visualization. Here, it’s used to visualize model training results. -
lime.lime_text.LimeTextExplainer: A module from LIME (Local Interpretable Model-agnostic Explanations) package. LIME is a way to explain predictions of any classifier in an interpretable and faithful manner. -
sklearn.preprocessing.OneHotEncoder: A class from scikit-learn library to perform one-hot encoding on categorical variables, used for transforming the class labels. -
sklearn.metrics.classification_report: A function from scikit-learn library that builds a text report showing the main classification metrics.
-
""" Import Packages to Use """
import os
import random
import numpy as np
import pandas as pd
import pickle
# For splitting joined words
import wordninja
# Import TensorFlow
import tensorflow as tf
# Text processing methods with TF
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.preprocessing.sequence import pad_sequences
# Check if any GPU is detected
print("Is GPU available: ", tf.test.is_gpu_available())
print("GPU(s) found: ")
print(tf.config.experimental.list_physical_devices('GPU'))
# For visualization
import matplotlib.pyplot as plt
%matplotlib inline
# For explaining URL classification predictions
from lime.lime_text import LimeTextExplainer
# We provide a function to prepare data as inputs to our classificaiton model.
# About how the data are processed, please refer to: text_processing_demo.ipynb.
from utils import preprocess_data
# Also, a function is prepared to takes URL string as input and returns the
# predicted category.
from utils import predict_url
-
Global Variables
Sets various global variables including those related to data size, text processing, and model parameters like vocabulary size, embedding dimension, learning rate, etc.
""" Global Variables """
# Set random seed
RAND_SEED = 9999
random.seed(RAND_SEED)
# Random seed for TensorFlow
tf.random.set_seed(RAND_SEED)
##### Data #####
# For demo purpose, we only use data of a subset of categories in this notebook
CATEGORIES_TO_USE = ['left','central','right']
N_CLASSES = len(CATEGORIES_TO_USE) # Number of classes to predict
# Size of training dataset
TRAIN_SIZE = 0.8
##### Text Processing #####
# Vocabulary size for tokenization
VOCAB_SIZE = 10000
# Maximum length of token sequence
MAX_LEN = 20
##### Classification Model #####
# Size of data batches
BATCH_SIZE = 40000
# Dimension of Word Embedding layer
EMBEDDING_DIM = 512
# Learning rate of optimizer
LR = 1e-3
# Number of epochs to train model
N_EPOCH = 100
Data Processing
The data is loaded from a CSV file containing URLs and their corresponding categories. For this demo, the categories have been limited to ‘left’, ‘central’, and ‘right’.
-
Load Data
""" Load Data """
# Specify root data directory
data_dir = os.path.join(module_dir, "data/")
# Path to data file
data_path = os.path.join(data_dir, "URL.csv")
# Load data into pandas DataFrame
data_df = pd.read_csv(data_path, header=None)
print("Example Data:")
print(data_df.head())
-
Split Data
The data is then shuffled and split into training and test sets. The division ratio is 80% for training and 20% for testing, as set by the variable TRAIN_SIZE.
""" Split Data into Training & Test Sets """
# First, shuffle the data, by shuffling indices.
idx_all = list(range(len(data_df)))
random.shuffle(idx_all)
# Find out where to split training/test set
m = int(len(data_df) * TRAIN_SIZE)
# Split indices
idx_train, idx_test = idx_all[:m], idx_all[m:]
# Split data
X_train, y_train = data_df.iloc[idx_train, 1].values, data_df.iloc[idx_train, 2].values
X_test, y_test = data_df.iloc[idx_test, 1].values, data_df.iloc[idx_test, 2].values
# Show dataset stats
print("Training set label distriubtion: ", np.unique(y_train, return_counts=True))
print("Test set label distriubtion: ", np.unique(y_test, return_counts=True))
-
Preprocess Data
Before training, the URLs (which are text) need to be converted into a format that can be understood by the model. This is done by word tokenization, using the preprocess_data function from the utils.py script. Word tokenization is the process of splitting a large paragraph into words. For example, “infococoonbreaker” -> [“info”, “cocoon”, “breaker”].
Next, these tokens are converted into integer tokens (a process called “integer encoding”) using the Tokenizer class from TensorFlow’s keras.preprocessing.text module. The size of the tokenizer’s vocabulary is 10,000 words, and sequences longer than 20 tokens are truncated.
The labels (categories) are also converted from string to one-hot encoded format. One-hot encoding is a process by which categorical variables are converted into a form that could be provided to machine learning algorithms to improve prediction. For example, the category ‘central’ would be converted to [1, 0, 0], ‘left’ to [0, 1, 0] and ‘right’ to [0, 0, 1].
""" Preprocess Data """
print("===== Before Preprocessing =====")
print("----- Training Data -----")
print("URL: ", X_train[0])
print("Category: ", y_train[0])
print("----- Test Data -----")
print("URL: ", X_test[0])
print("Category: ", y_test[0])
print("================================")
# First, we process the training data. While processing the training data, a
# tokenizer and an encoder are constructed based on the training inputs and
# labels, resp. The function preprocess_data(...) returns the tokenizer and
# encoder used.
X_train, y_train, tokenizer, encoder = preprocess_data(
X_train, y_train, return_processors=True,
)
# Based on the tokenizer and encoder constructed from training data, we process
# the test data here too.
X_test, y_test = preprocess_data(
X_test, y_test,
tokenizer=tokenizer, encoder=encoder,
)
print("===== After Preprocessing =====")
print("----- Training Data -----")
print("Input: ", X_train[0])
print("Label: ", y_train[0])
print("----- Test Data -----")
print("Input: ", X_test[0])
print("Label: ", y_test[0])
print("================================")
-
TensorFlow Dataset Pipeline
The preprocessed data is then fed into a TensorFlow dataset pipeline for training the model in batches. The size of each batch is 40,000.
""" TensorFlow Dataset Pipeline """
# A TF dataset pipeline is prepared here for feeding input batches to train the
# model later.
# Training set data pipeline
train_ds = tf.data.Dataset.from_tensor_slices((X_train, y_train)) # Input: tokenized urls, target labels
train_ds = train_ds.shuffle(buffer_size=len(X_train)) # Shuffle training data
train_ds = train_ds.batch(batch_size=BATCH_SIZE) # Split shuffled training data into batches
# Test set data pipeline
test_ds = tf.data.Dataset.from_tensor_slices((X_test, y_test))
test_ds = test_ds.batch(batch_size=BATCH_SIZE)
Modeling
The model is a sequential model built using Keras, a high-level API to build and train models in TensorFlow. It consists of an embedding layer, a GlobalAveragePooling1D layer, a dense layer with ‘relu’ activation function, and a final dense layer with ‘softmax’ activation function.
-
Model Construction
# Construct a neural network
model = tf.keras.Sequential([
tf.keras.layers.Embedding(VOCAB_SIZE, EMBEDDING_DIM, input_length=MAX_LEN),
tf.keras.layers.GlobalAveragePooling1D(),
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dense(N_CLASSES, activation='softmax')
])
# Compile model
model.compile(loss='binary_crossentropy',
optimizer=tf.keras.optimizers.Adam(LR),
metrics=['accuracy'])
# Show model structure
print(model.summary())
-
Model Training
The model is then trained using the Adam optimizer with a learning rate of 1e-3, binary cross-entropy as the loss function, and accuracy as the metric to measure model performance.
""" Train Model """
history = model.fit(train_ds, epochs=N_EPOCH,
validation_data=test_ds, verbose=1)
Result
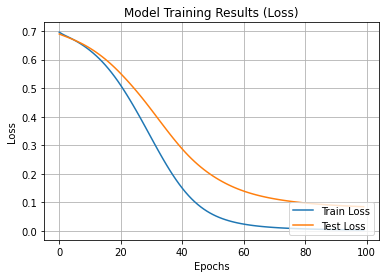
The model is trained for 100 epochs. At each epoch, the model’s performance (loss and accuracy) on the training data and the test data is recorded and later visualized using Matplotlib.
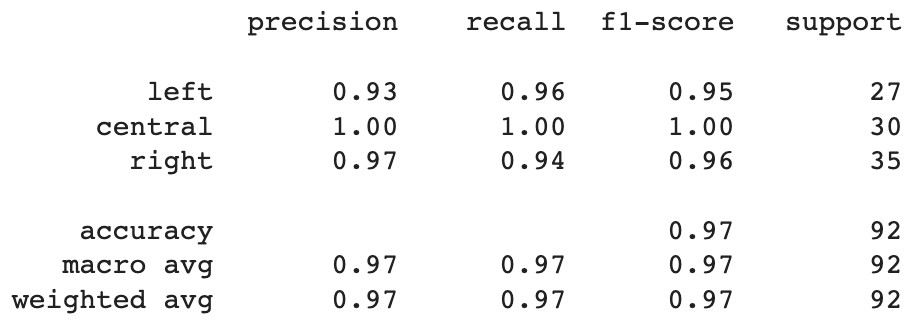
After training, the model’s performance is evaluated by precision and recall, using the Scikit-learn library’s classification_report function.
-
Loss Rate and Accuracy
""" Visualize Training Results """
##### Loss #####
# Get training results
history_dict = history.history
train_acc = history_dict['loss']
test_acc = history_dict['val_loss']
# Plot training results
plt.plot(train_acc, label='Train Loss')
plt.plot(test_acc, label='Test Loss')
# Show plot
plt.title('Model Training Results (Loss)')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend(loc="lower right")
plt.grid()
plt.show()
##### Accuracy #####
# Get training results
history_dict = history.history
train_acc = history_dict['accuracy']
test_acc = history_dict['val_accuracy']
# Plot training results
plt.plot(train_acc, label='Train Acc.')
plt.plot(test_acc, label='Test Acc.')
# Show plot
plt.title('Model Training Results (Acc.)')
plt.xlabel('Epochs')
plt.ylabel('Acc')
plt.legend(loc="lower right")
plt.grid()
plt.show()
-
Precision and Recall
""" Precision & Recall """
# Sklearn provides the classificatiaon_report(...) function which makes
# evaluation of classification model easy.
from sklearn.metrics import classification_report
print(classification_report(
np.argmax(y_test, axis=1), # ground-truths
np.argmax(model.predict(X_test), axis=1), # predictions
target_names=CATEGORIES_TO_USE)
)